
Byg en chatbot på din data helt uden at skulle kode
Skrevet afRasmus Luckow-Nielsen
Adm. direktør i Reload
Forestil dig din egen virtuelle butler. Den kender din organisation bedre end alle andre, og du kan spørge den til råds om alt muligt, hvor den rent faktisk giver meningsfulde svar.
Lyder fedt, ikke?

Chatbot fikser tingDe samme spørgsmål igen og igen
Hvis du er leder, så kender du måske det med, at folk kommer og spørger dig om det samme igen og igen: “Hvordan registrerer jeg ferie?” eller “Hvad skal jeg gøre hvis jeg bliver syg?” og “Har vi en politik for _______?” Som medarbejder, så ved du, at selvom det måske allerede står i en personalehåndbog eller en politik et sted, så kan det være svært lige at finde. Det er nok bare nemmere at forstyrre chefen …
Hvad hvis vi kunne gøre al den information nemt tilgængelig for alle? Og dermed udbrede viden og samtidig spare tid? Tilmed kan det gøre det meget nemmere for nye folk i organisationen at finde svar på de mange spørgsmål, man nu engang har.
Perspektivet er vidtrækkende.
Mød Hubot!
I Reload har vi eksperimenteret med at lave vores egen “custom” GPT chatbot baseret på vores data. Vi har fodret den med vores personalehåndbog, procesbeskrivelser, politikker, artikler og alt andet der ofte bliver spurgt ind til.
Vi kalder vores bot for “Hubot”:
Hubot fungerer faktisk ret godt, og det krævede ikke det store at sætte op. I fremtiden håber vi på at kunne koble den sammen ved vores interne chatsystem, således at den er nem at få fat i, men lige nu tillader OpenAI ikke dét, så det kræver en konto ovre hos dem på deres hjemmeside.
Hvad du får ud af denne artikel
I denne artikel vil jeg vise dig, hvordan jeg har gjort, og så kan det forhåbentligvis inspirere dig til at prøve denne stadigvæk umodne teknologi af.
Vi bygger en GPT bot i OpenAI, og det kræver en konto i OpenAI at gøre. Det at bygge en bot tager ikke mange minutter og er faktisk meget intuitivt. Det som er svært, det er rent faktisk at få din egen data ind i maven på denne GPT. Så det vil jeg komme med nogle tips omkring.
Sidst men ikke mindst, så skal man også give botten nogle instruktioner, således den svarer som du ønsker det og ikke hallucinerer alt for meget. Lad os dog lige starte med det dødkedelige. Nemlig begrænsninger og jura.
Begrænsninger
I skrivende stund (medio marts 2024) så er der en række begræsninger i OpenAIs GPTs, som gør, at en masse ting, som kunne være smarte, endnu ikke kan lade sig gøre. Jeg forventer dog, at det inden årets udgang vil være åbnet væsenligt mere op for.
Du kan ikke integrere GPT med eksterne systemer. Dvs. du kan ikke få din bot til at leve uden for OpenAIs system. Du kan dog godt dele den med andre, som har en OpenAI konto.
Da der ikke er nogen API adgang til GPTs, så kan du heller ikke automatisk opdatere GPT’ens datakilder. Det er en manuelt upload proces.
Performance er svingende. Det kan gå fra rimelig tjept til fuldstændig uudholdeligt. Det hjælper dog gevaldigt, hvis datakilder er i TXT format.
GPT’er kan underligt nok ikke browse på internettet, så man kan pt. ikke både få den til at kende din egen data og kigge på internettet samtidig, hvilket bare er underligt og ærgerligt.
Overvejelser om data, etik og GDPR
Du skal jo altid gøre dig nogle overvejelser omkring data, du smider i chatbots og andre systemer, du ikke selv ejer og kan styre.
I vores tilfælde, så har vi ikke noget følsom data, og derfor vurderer vi ikke, at der er nogen risici ved at lægge data op i OpenAIs systemer. Med deres Teams plan, så lover de for øvrigt også, at de ikke vil træne/bruge den data, man bruger. Men tommelfingerreglen må være, at du ikke skal lægge data i en AI-model, som ikke kan tåle offentlighedens lys.
Men lad os komme igang med det sjove! Lad os bygge en bot, og fodre dem med vores egen data.
Tutorial-time!Sådan gør du
Først og fremmest skal du oprette en konto - og den skal være betalt. Så er det sagt. Derefter så skal du ind under Explore GPTs, og så kan du selv oprette en ny GPT. Så burde din skærm gerne se således ud:
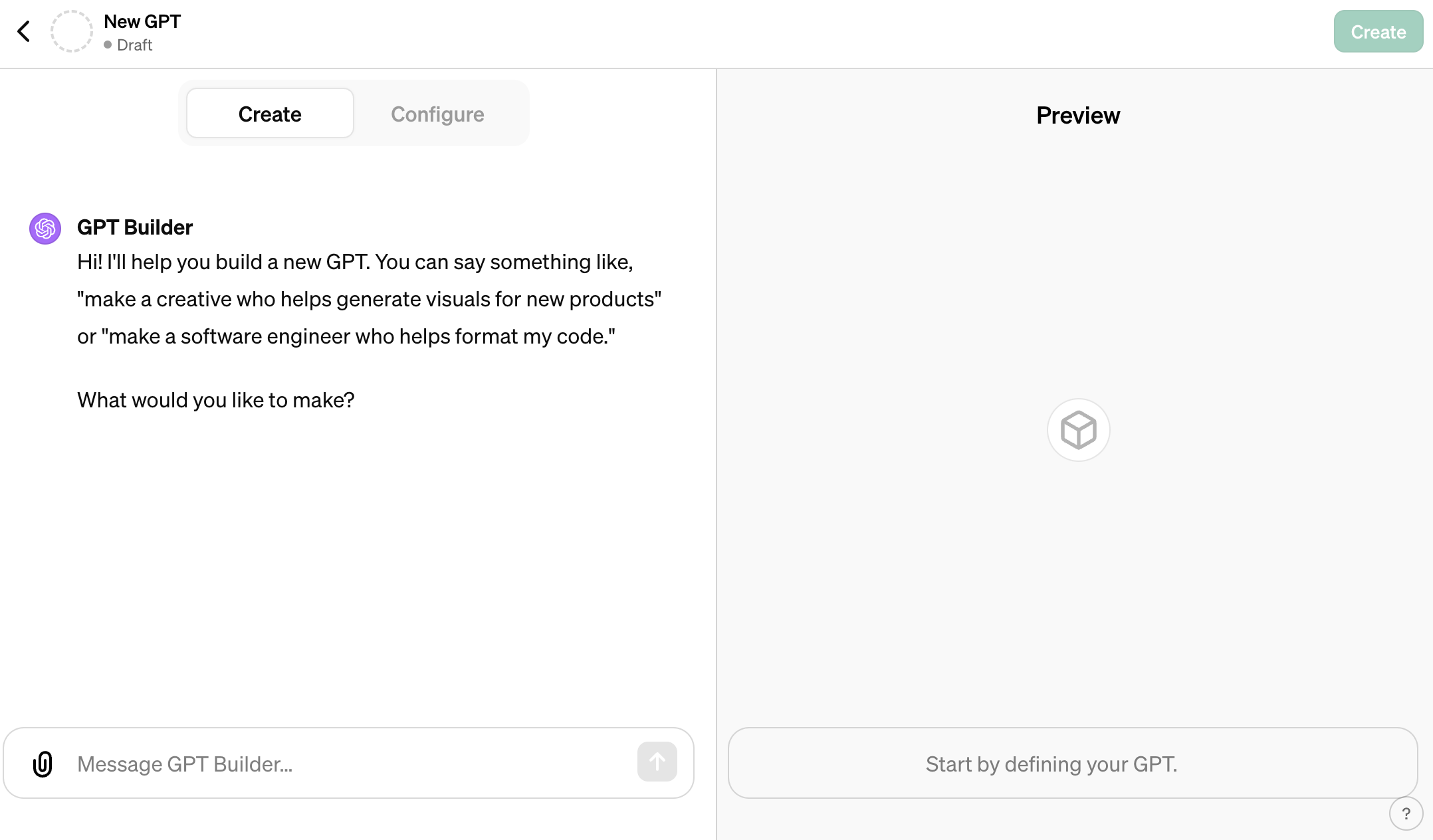
Der er forskellige ting, du kan gøre, men det er egentlig ret let. Vores helt egen “Hubot” er f.eks. meget simpelt sat op. Her er instruktionerne:

Vi har fodret Hubot med fire datakilder:
Vores personale håndbog mm (vi kalder det Reloads “Wiki”), som også indeholder alle vores politikker, guides og procedurer.
Alle sider og artikler fra vores website (som du er på nu).
En e-bog omkring vores agile processer, som vi har skrevet.
The Reload Way, som er en beskrivelse af Reloads historie, kultur, organisering og beslutningsprocesser.
Og vupti, nu har du faktisk en ganske vidende chatbot, og jeg synes, den svarer imponerende rigtigt!
Tips og tricksTips til datakilder og performance
I princippet kan du uploade alt muligt fra Word- og Excel-filer til PDF’er osv. Men jeg har oplevet, at det giver en dårlig performance. GPT’en skal simpelthen tygge på data i ulidelig lang tid, før der kommer svar.
Så første tip er, at du skal eksportere dine data til rå tekst-filer. Det gør ikke noget, at det for et menneske ligner noget, der er løgn. Sprogmodellen her er virkelig god til at uddrage mening og struktur af de massive mængder af tekst.
I praksis har jeg gjort følgende:
Downloadet og eksporteret e-bog og The Reload Way som TXT fra Google Drive, hvor vi har originaldokumenterne i dag.
Eksporteret hele vores “wiki” som HTML. Herefter har jeg konverteret og samlet det i én stor TXT fil.
Crawlet Reload.dk, downloaded alt som HTML, og herefter konverteret og samlet det hele i én stor TXT fil.
Så hvordan gør man lige det, tænker du måske?
Hvis du er heldig, så kan du eksportere ting til TXT i dine systemer/værktøjer. Og ellers er det at være lidt kreativ.
Der findes givetvis en række onlineværktøjer der kan hjælpe, men den gamle tekniker i mig mente at jeg burde kunne klare det selv.
Jeg sidder på en Mac, og den har en dejlig terminal, som man kan fyre nogle kommandoer af på.
HTML -> TXT
Så er du på en Mac, så kan du køre denne kommando i Terminalen, hvis du har en mappe fuld af .html filer:

find . -name '*.html' -exec sh -c 'textutil -convert txt -stdout "{}"; echo "\n---- NY-WEBPAGE ----\n"' \; > samlet_website.txtDet resulterer så i en fil, der her er navngivet “samlet_website.txt”.
Download dit website
For lidt at gøre det en tand mere komplekst, så får du her også lige en kommando til at hente alt indhold på en hjemmeside.
Når det er sket, så skal du så også konvertere det til TXT, som vist ovenfor. Alt downloade alt indhold fra en hjemmeside tager tid (timer!), fordi jeg indsætter en pause på 5 sekunder mellem hver request, fordi du ellers risikerer at lægge et website ned - eller at hosten blokerer dig.

wget --recursive --html-extension --no-clobber --convert-links -w 5 https://reload.dk
Da det pt. er en manuel proces der sker her, så navngiver jeg filerne med en dato, således jeg kan se hvornår det er blevet opdateret. I fremtiden vil det jo være meget smartere at opdateringer sker automatisk, men lige nu er det ikke noget problem at gøre det manuelt med nogle måneders mellemrum - så ofte sker der ikke ændringer i disse data.
OpenAI har ikke givet adgang til at kunne gøre dette automatisk - endnu.
Fremtidsperspektiver
Lige nu er teknologien mest til at man kan lege med den. Vi har fx også bygget en “ContentBot”, som fodret med vores nyhedsbreve og artikler kan hjælpe os med at skrive nyt indhold, men med stil, tone og inspiration fra det eksisterende indholdsunivers.
Men lige så snart, at du kan få en bot til at absorbere dine interne data, der løbende automatisk kan opdateres, og derved eksponere det i et let og tilgængeligt format overfor brugere, jamen så bliver det rigtig interessant. Det vil komme til at revolutionere søgning og vidensdeling - både internt i organisationer, men da også i fht. udefrakommende brugere.
Jeg vil tro, at det snart bliver muligt fra off-the-shelf produkter, såsom OpenAI, men der er selvfølgelig også allerede i dag mulighed for at downloade open source sprogmodellerne som ligger bag, og så skræddersy dem til organisationers behov.
Det bliver inden for en overskuelig fremtid både nemt og billigt - så det kommer vi til at se meget mere af.
Kontakt
Har du spørgsmål?
Jeg er altid klar på at sparre, snakke videre eller svare på spørgsmål! Send endeligt en e-mail min vej, og så snakkes vi ved.


